Happy New Year! I took yesterday off, so this week’s AI Week comes on the first non-holiday day of 2024.
If you don’t read anything else in this blog post, read the first and last items: the NYT is suing OpenAI, and my 10 predictions for AI and society in 2024. (But if you do that, you’ll miss the chocolate cake.)
- NYT sues OpenAI over training data (plus: US mulls forced disclosure of training data; recap of 2023 lawsuits; meanwhile, Apple explores deals)
- Longreads and not-so-long-reads
- AI generates all the things, recipe edition
- 10 predictions for 2024
I’d love to hear your comments about anything in this post, but especially the predictions. Please leave your comments below!
Read the rest on ButtonDown, or continue below.
Get these blog posts as a newsletter
NYT sues OpenAI and Microsoft
NYT sued OpenAI in the last week of December, and went for the nuclear option: The NYT is asking for nothing less than the destruction of OpenAI’s GPT models.
The background
As a recap, in November 2022 OpenAI released ChatGPT, an impressively human-like chatbot based on its large language model (LLM) GPT-3.5. To create and fine-tune this LLM, OpenAI had to train it on hundreds of gigabytes of text, mostly scraped from the Internet. OpenAI has been less than forthcoming about what they used, but as 2023 progressed, some of its sources were revealed, including:
- Ebooks, including copyrighted books used without permission
- The Enron emails dataset
- Wikipedia
- Web pages
Originally, OpenAI claimed that although this training data was used to build and tune its models, the data was not part of the models: supposedly, the training data wasn’t stored in the model, and the LLM wouldn’t regurgitate it but transform it, making OpenAI’s wholesale use of copyrighted texts a “transformative use” and therefore not a copyright violation; nothing to see here, move along, etc.
However, as 2023 progressed, researchers found that this wasn’t strictly true, publishing papers with titles like “Bag of Tricks for Training Data Extraction from Language Models”. Then, in November 2023, researchers published a paper showing that chunks of this training data could be extracted from ChatGPT-3.5 wholesale.
The lawsuit
Last week, the New York Times sued OpenAI and ChatGPT, noting they could get ChatGPT and Microsoft Copilot to regurgitate copyrighted New York Times articles.
https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html
Here’s a screenshot from Gary Marcus’s blog comparing GPT-4 output to a NY Times article. Red text is identical:

Reporters at Ars Technica found that they could easily get Microsoft Copilot to spit out the first third of a Times article, by prompting it with the first paragraph.
The Times’ lawsuit has this to say about the “fair use” defense:
“Publicly, Defendants insist that their conduct is protected as ‘fair use’ because their unlicensed use of copyrighted content to train GenAI models serves a new ‘transformative’ purpose,” the suit notes. “But there is nothing ‘transformative’ about using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.”
How it came to this
Last week, I mentioned that OpenAI came to a deal with Axel Springer (Business Insider) and the Associated Press to use their content for training–negotiated without input from the authors, who weren’t even informed until the deal was done. The NYT notes that they had attempted to come to some kind of deal with OpenAI before filing the suit, but couldn’t reach an agreement.
Why this is a big deal: it’s an existential issue
Per Ars Technica, “the suit seeks nothing less than the erasure of both any GPT instances that the parties have trained using material from the Times, as well as the destruction of the datasets that were used for the training. It also asks for a permanent injunction to prevent similar conduct in the future.”
This is an existential issue, not just for OpenAI, but for the current slate of generative AI. Venture capital firm Andreessen Horowitz (a16z) told the US Copyright office that “imposing the cost of actual or potential copyright liability on the creators of AI models will either kill or significantly hamper their development.”
US mulls forced disclosure of training data
OpenAI has not been upfront about what data it used for training; the NYT was only able to confirm that its articles were used because ChatGPT and Copilot regurgitated them. (Speaking of regurgitating training data, the NYT was not pleased to note that ChatGPT will also reveal its staffers’ email addresses) A new US bill, the AI Foundation Model Transparency Act, would require disclosure of training data.
More 2023 Training Data Lawsuits
This is far from the first lawsuit filed about training AI models on copyrighted data without permission. A quick recap of some of this year’s lawsuits:
⁃ Authors Guild and 17 authors suing OpenAI
⁃ Sarah Silverman and others are suing OpenAI and Meta
⁃ Authors Paul Tremblay and Mona Awad are suing OpenAI
⁃ Cartoonist Sarah Andersen (Sarah’s Scribbles) and others are suing over Stable Diffusion
⁃ Getty is suing Stability AI in the UK for using its stock images without permission
⁃ A law firm is suing Microsoft over Copilot (the coding assistant part) on behalf of GitHub users
⁃ Universal Music is suing Anthropic, makers of ChatGPT rival Claude, over scraping song lyrics
Expect more lawsuits in 2024
<
p class=”has-line-data” data-line-start=”78″ data-line-end=”79″>I mentioned a few weeks ago that Bing was really much too good at generating the Disney logo. Generative AI image-generation users have been noticing that even vague prompts can result in copyright-straining images like Super Mario™) with a can of Coke™ (prompt “Game plumber and red soda drink with logo”).
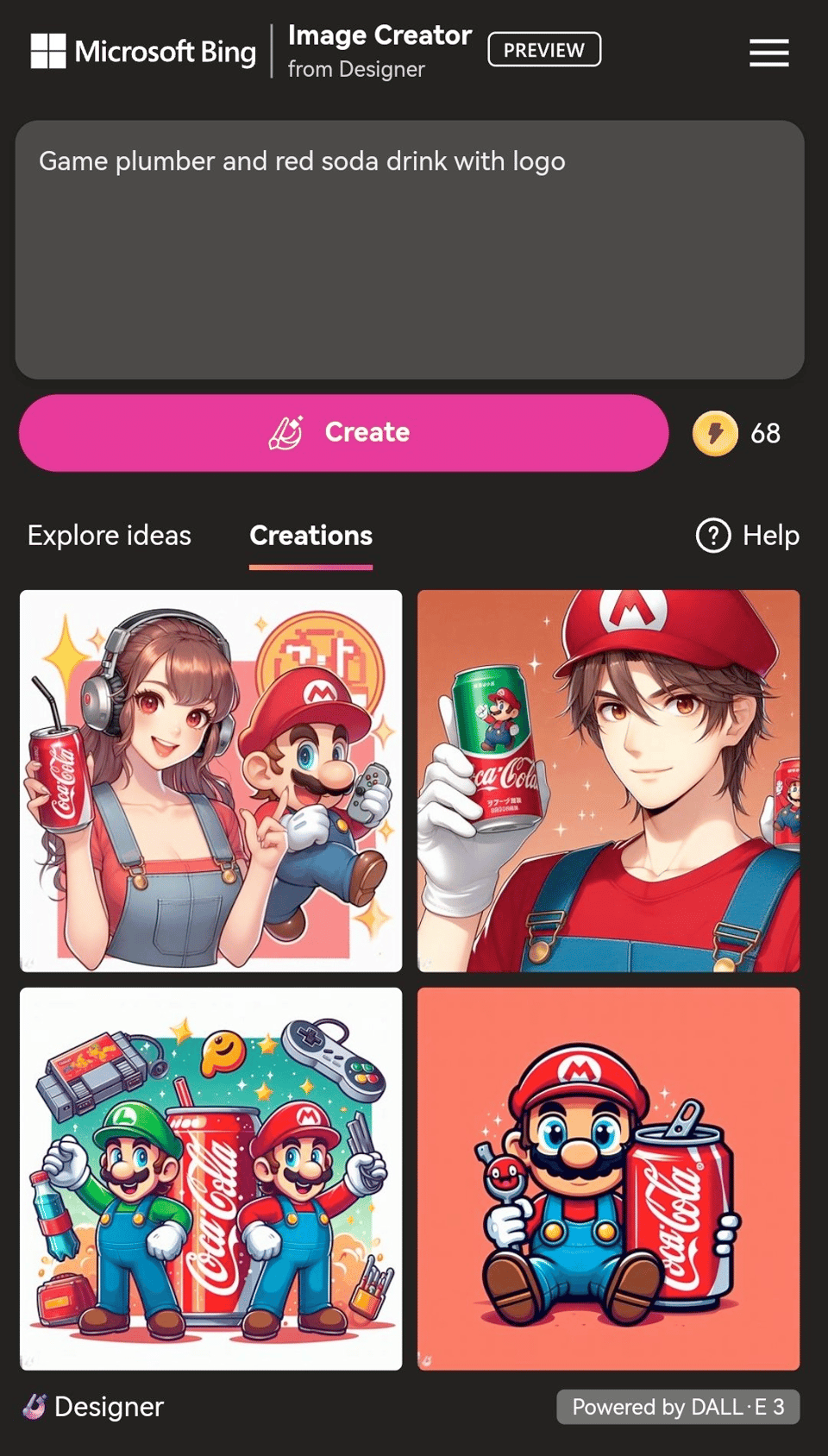
Source: https://nitter.net/Blanketman_01/status/1740801789157654805#m
Microsoft Bing’s image creator has been spitting out Sonic the Hedgehog, Super Mario, Magic the Gathering cards and more.
There is probably no easy fix for this. It’s increasingly clear that this year’s stunning advances in generative AI required training with mounds of copyrighted data, and trying to stop their outputs from reflecting that training is turning into a game of Whack-A-Mole. As Gary Marcus predicts, “things are about to get a lot worse for Generative AI”
Meanwhile, Apple explores deals
with companies like Condé Nast (Ars Technica, Vogue), NBC News, and IAC
https://www.theverge.com/2023/12/22/24012730/apple-ai-models-news-publishers
Longreads
2023 was a crazy year for generative AI. Here are a couple of “What happened in 2023” catch-ups from two different viewpoints.
First, for the authors’ perspective on 2023, Jason Sanford, who puts out a Patreon newsletter for speculative fiction authors, has published a compilation of his 2023 articles about AI.
https://www.patreon.com/posts/genre-grapevines-95628069
Second, for the engineers’ perspective on 2023, the IEEE spectrum recaps their top 10 AI stories of 2023:
https://spectrum.ieee.org/ai-news-2023
Not-so-long reads
Is AI regulation in the US underfunded?
Charged with regulating AI but underfunded, NIST may ask AI companies how to regulate themselves
https://arstechnica.com/ai/2023/12/us-agency-tasked-with-curbing-risks-of-ai-lacks-funding-to-do-the-job/
ChatGPT will lie, cheat and use insider trading when under pressure to make money, research shows
A reader shared this recent LiveScience report about a November preprint (i.e., non-peer-reviewed paper) shared on arXiv.
GPT-4 has been fine-tuned (trained) to respond honestly and helpfully, but to avoid giving responses that could hurt others, a process known as alignment. However, when researchers told GPT-4 it was a stock trader, then sent it a simulated “email” from its “manager” telling it they needed profits, GPT-4 went straight to insider trading and lied about it.
As I mentioned above, OpenAI used the Enron email corpus for training–in fact, it seems to have been used in GPT-4’s fine-tuning… so this misalignment maaaaybe shouldn’t be a surprise.
AI generates all the things, recipe edition
In this week’s “AI generates all the things,” we have a couple of stories about AI-generated recipes.
AI-generated cake recipes

In a head-to-head recipe test, a ChatGPT-generated cake recipe beat out an actual, human-generated recipe from Sally’s Baking Blog. (The cake recipe from Google’s chatbot, Bard, did not.) But the cake recipe still wasn’t as good as one from a really good cookbook.
Image: “Chocolate cake, made of computer parts, cyberpunk, digital art” generated in NightCafe Studio Stable Diffusion XL-based model Starlight XL. As mentioned above, Stability AI is being sued by several artists; this image is for non-commercial use only, & was generated using a free mode (no payment from me to Stability AI)
Fridge-generated recipes
Touchscreens on fridges, and fridge-based computing in general, have always seemed to me like a solution in search of a problem. (Why do I want to look things up on my fridge when I could just bring my phone into the kitchen, right?) Samsung’s 2024 AI-boosted fridge seems like it’s aiming to provide solutions to some actual problems, such as “What’s in my fridge?” and “What can I make with the things in my fridge?” The fridge can only recognize “up to 33 food items,” though, which is somehow both impressive (my fridge can recognize things?!) and disappointing (it probably can’t tell me what to make with leftover takeout).
https://www.theverge.com/2023/12/27/24016939/samsung-2024-ai-family-hub-smart-fridge-features
Beef and eggnog salad
ChatGPT, Bard, and your future Samsung fridge are far from the only ways to generate a recipe with AI: check out some more here. These are foundation LLMs that have been trained for recipe generation. I gave one of them, LetsFoodie.com a list of what I had in my fridge, and was rewarded with a recipe for “Creamy Beef and Cheese Pasta Salad with a Tangy Lemon Dressing” that incorporated every single thing in the list, including eggs scrambled with eggnog. Hopefully the Samsung proto-fridge will be better at leaving ingredients out.
I asked Craiyon (formerly known as Dall-E Mini) to create an image of the full salad. It wouldn’t add the scrambled eggnog-eggs, beans, cheese, pickles or olives; however, I did get this beef pasta salad with blood-daubed lemon-eggs.

(If you’re curious, my prompt was: “Please make a picture of a Creamy Beef and Cheese Pasta Salad with a Tangy Lemon Dressing. The salad has the following ingredients: roast beef, eggnog, milk, eggs, celery, juice, ketchup, soy sauce, blue cheese, cheddar cheese, apples, lemons, beans, pasta, rice, pickles, olives. The roast beef is browned. The eggs are scrambled with eggnog and milk. The beef and eggs are mixed with the pasta and served on a bed of lettuce, with the beans, pickles, olives, and cheese poured over top.” And yes, that’s an accurate description of the recipe. No, I wasn’t tempted to make it.)
Another solution in search of a problem: the AI Pin
Speaking of solutions in search of problems: Humane released a device that got a lot of pre-release buzz, its “AI Pin.” Basically, this is a Star Trek-like communicator, but instead of communicating with someone on the bridge of the Enterprise, you get to talk to ChatGPT. The Verge describes it as “something of a wearable LLM-powered search engine.”
https://www.theverge.com/2023/11/9/23953901/humane-ai-pin-launch-date-price-openai
10 predictions for 2024
It’s January 2nd, here are my guesses about what the new year will hold.
- 10. 2024 will be the year of AI solutions in search of a problem.
- 9. We’ll see a lot more “AI mistakes” stories, like the Cadillac dealership’s chatbot that tried to sell someone a Ford, and more misalignment
- As AI assistants are deployed in new applications, they’ll find new ways to mess up.
- There’s probably no easy fix for “misalignment”, which is when the safeguards around generative AI fail and it generates toxic content (bomb instructions, non-consensual nudes, hate speech, etc)
- 8. More on-device AI
- Apple is working on it; Google has Gemini Nano; Microsoft just put Copilot on Android
- 7. More alternatives to ChatGPT and Stable Diffusion
- ByteDance was caught ripping off ChatGPT to develop its own AI
- Small language models and open-source models continue to get better
- But don’t expect more OpenAIs or Anthropics: the big tech players are already outspending VCs now https://arstechnica.com/ai/2023/12/big-tech-is-spending-more-than-vc-firms-on-ai-startups/
- I could be wrong – the “more lawsuits” (#3 and also above) could discourage this.
- Look for attempts at “ethically trained” (eg, all-public-domain) models
- 6. More job openings that amount to “AI supervisor”
- For example: less translation jobs, more jobs to "check this AI translation over and make sure it’s not inflating the jellies" (if you didn’t get that reference, check out the bonus item in the Nov. 27th newsletter)
- 5. More AI in policing and intelligence
- The NYT reported last week on an AI-powered intelligence system commissioned by China’s Ministry of State Security
- 4. Some layoffs, some eventually followed by hire-backs
- Google’s ad department, which is reportedly shedding some jobs now done by generative AI
- Some layoffs will be overly optimistic about the capability of shiny new AI solutions… and some humans will be hired back following embarrassing incidents
- 3. More lawsuits, and eventually (though probably not in 2024) some judgements
- 2. More legislation to regulate AI, in the vein of the EU’s AI act
- 1. 2024 will be the first US election that will be influenced by generative AI, and it’s going to be a shitshow.
Let’s talk more about that last one. Here are a few of the ways generative AI is poised to influence elections:
- Researchers have demonstrated how to make chatbots generate toxic speech (see last week’s AI Week for a rundown
- AI is already being used to create political speech and propaganda campaigns
- Deepfaked news is a thing now, complete with deepfaked anchors, deepfaked video, and deepfaked clips of real people saying stuff they didn’t say
So it’s a big problem that people are largely unaware that posts, videos and stories on social media may be fake: a couple of weeks ago, I mentioned that Facebook is already flooded with AI-generated images, and people think they’re real.
The upshot is that social media’s going to be deluged with convincing fakes by domestic and foreign actors; sketchy networks like ONN and Fox will gleefully replay these fakes, giving them legitimacy; outraged voters will go to the polls believing they saw a candidate stealth-vaccinating other people’s babies, or eating a kitten, or whatever.
That was a bummer, so here’s a kitteh

Comments or thoughts? Please share below.