One of the amazing things about being a DBA/developer in 2016 is the sheer amount of freely available, downloadable data to play with. One fun publicly available data sets is the American Social Security Administration names data. It contains all names for which SSNs were issued for each year, with the number of occurrences (although names with <5 occurrences are not included to protect individual privacy).
What’s so fun about this dataset?
* It’s already normalized
* It updates only once a year, and then only by adding another year’s worth of data, so it’s easy to keep current
* Almost everyone can relate to this dataset personally – almost everyone’s name is in there!
* At about 1.8 million rows, it’s not particularly large, but it’s large enough to be interesting to play with.
The one slight annoyance is that the data is in over 100 files, one per year: too many to load one-by-one manually. So here’s a blog post on loading it into your Oracle database, with scripts.
1. Visit the URL:
https://catalog.data.gov/dataset/baby-names-from-social-security-card-applications-national-level-data
2. Download and unzip names.zip . This zip archive contains one file for each year from 1880 to 2015. The files are named yobXXXX.txt eg. yob2015.txt .
3. Create a table to hold the names data:
DROP TABLE names; CREATE TABLE names (YEAR NUMBER(4), name varchar2(30), sex CHAR(1), freq NUMBER);
4. Load in one year to get a feeling for the data. Let’s load “yob2015.txt”, the most recent year.
Here’s a sql*loader control file “names.ctl” to load the data:
[oracle@localhost names]$ cat names.ctl
load data
infile 'yob2015.txt' "str '\r\n'"
append
into table NAMES
fields terminated by ','
OPTIONALLY ENCLOSED BY '"' AND '"'
trailing nullcols
( NAME CHAR(4000),
SEX CHAR(4000),
FREQ CHAR(4000),
YEAR "2015"
)(By the way, here’s a great tip from That Jeff Smith: Use sql developer to generate a sql*loader ctl file. )
Now let’s use the ctl file to load it:
[oracle@localhost names]$ sqlldr CONTROL=names.ctl skip=0 Username:scott/******** SQL*Loader: Release 12.1.0.2.0 - Production on Thu Jun 9 10:41:29 2016 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. Path used: Conventional Commit point reached - logical record count 20 ... Table NAMES: 32952 Rows successfully loaded. Check the log file: names.log for more information about the load.
5. Let’s take a look at the 2015 data! How about the top 10 names for each sex?
WITH n AS ( SELECT name, sex, freq, rank() OVER (partition BY sex ORDER BY freq DESC) AS rank_2015 FROM names WHERE YEAR=2015 ) SELECT * FROM n WHERE rank_2015 < 11 ORDER BY sex, rank_2015;
NAME S FREQ RANK_2015 ------------------------------ - ---------- ---------- Emma F 20355 1 Olivia F 19553 2 Sophia F 17327 3 Ava F 16286 4 Isabella F 15504 5 Mia F 14820 6 Abigail F 12311 7 Emily F 11727 8 Charlotte F 11332 9 Harper F 10241 10 NAME S FREQ RANK_2015 ------------------------------ - ---------- ---------- Noah M 19511 1 Liam M 18281 2 Mason M 16535 3 Jacob M 15816 4 William M 15809 5 Ethan M 14991 6 James M 14705 7 Alexander M 14460 8 Michael M 14321 9 Benjamin M 13608 10
6. Now let’s load the names data for the other 135 years.
First we’ll create a generic “names.ctl”:
$ cat names.ctl
load data
infile 'yob%%YEAR%%.txt' "str '\r\n'"
append
into table NAMES
fields terminated by ','
OPTIONALLY ENCLOSED BY '"' AND '"'
trailing nullcols
( NAME CHAR(4000),
SEX CHAR(4000),
FREQ CHAR(4000),
YEAR "%%YEAR%%"
)Now we’ll write a small shell script to substitute %%YEAR%% for each year from 1880 to 2014, and load that year’s file.
$ cat names.sh #!/usr/bin/bash export TWO_TASK=orcl for i in {1880..2014} do echo "generating yob$i.ctl" sed s/%%YEAR%%/$i/g names.ctl > yob$i.ctl echo "loading yob$i" sqlldr username/password CONTROL=yob$i.ctl echo "done $i" done [oracle@localhost names]$ ./names.sh ... massive screen output... [oracle@localhost names]$ grep "error" *.log yob1880.log: 0 Rows not loaded due to data errors. yob1881.log: 0 Rows not loaded due to data errors. yob1882.log: 0 Rows not loaded due to data errors. yob1883.log: 0 Rows not loaded due to data errors. ... yob2012.log: 0 Rows not loaded due to data errors. yob2013.log: 0 Rows not loaded due to data errors. yob2014.log: 0 Rows not loaded due to data errors.
7. Now we can play with the data a bit!
Here’s a quick look at the popularity of 2015’s top girls’ names since 1880:
WITH n2015 AS ( SELECT name, sex, freq, rank() OVER (partition BY sex ORDER BY freq DESC) AS rank_2015 FROM names WHERE YEAR=2015 ) , y AS (SELECT YEAR, sex, SUM(freq) tot FROM names GROUP BY YEAR, sex) SELECT names.year, names.name, 100*names.freq/tot AS pct_by_sex FROM n2015, y, names WHERE n2015.name = names.name AND n2015.sex = names.sex AND y.year = names.year AND y.sex=names.sex AND n2015.rank_2015 < 11 AND y.sex='F' ORDER BY YEAR, name;
I graphed this in SQL Developer. Click to embiggen:
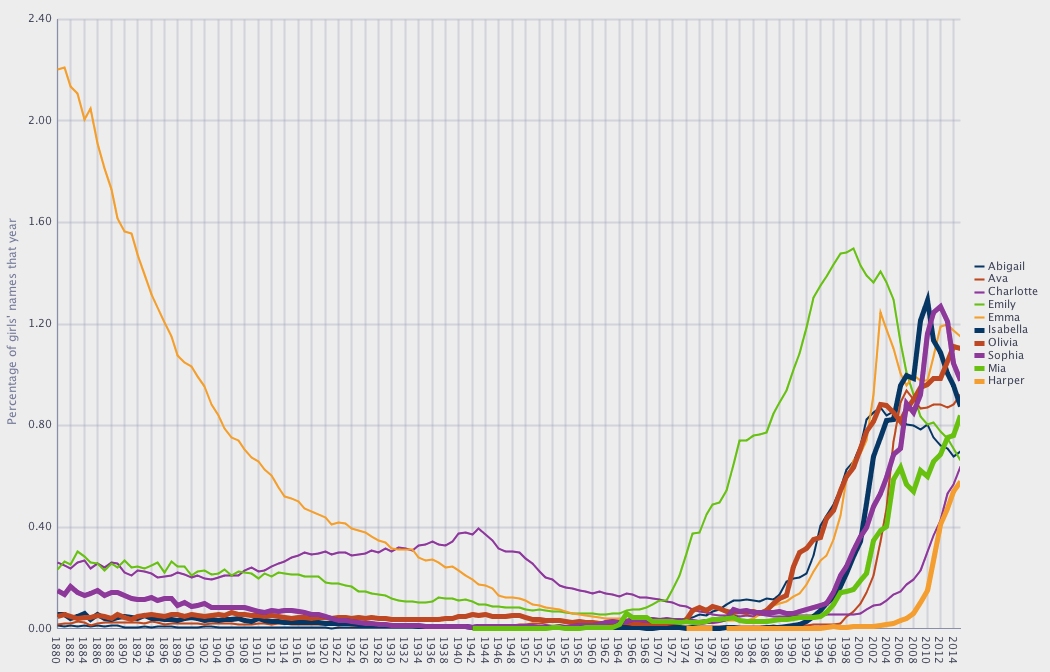
You can see that Emma, my grandmother’s name, is having a bit of a comeback but is nowhere near the powerhouse it was in the 1880s, when 2% of all girls were named Emma. (For the record, my grandmother was not born in the 1880s!)
My next post will look at the name Brittany and its variants.
Note: You can download the names.ctl and names.sh from github here.
One comment